isthisai.lol DECOMMISSIONED
A small game where you guess whether an asset is AI generated or not.
What it is
A small game where the user picks whether a given asset is AI generated or not. The idea came from noticing how popular r/isthisai and r/isitAI had become, and turning that same instinct into something interactive.
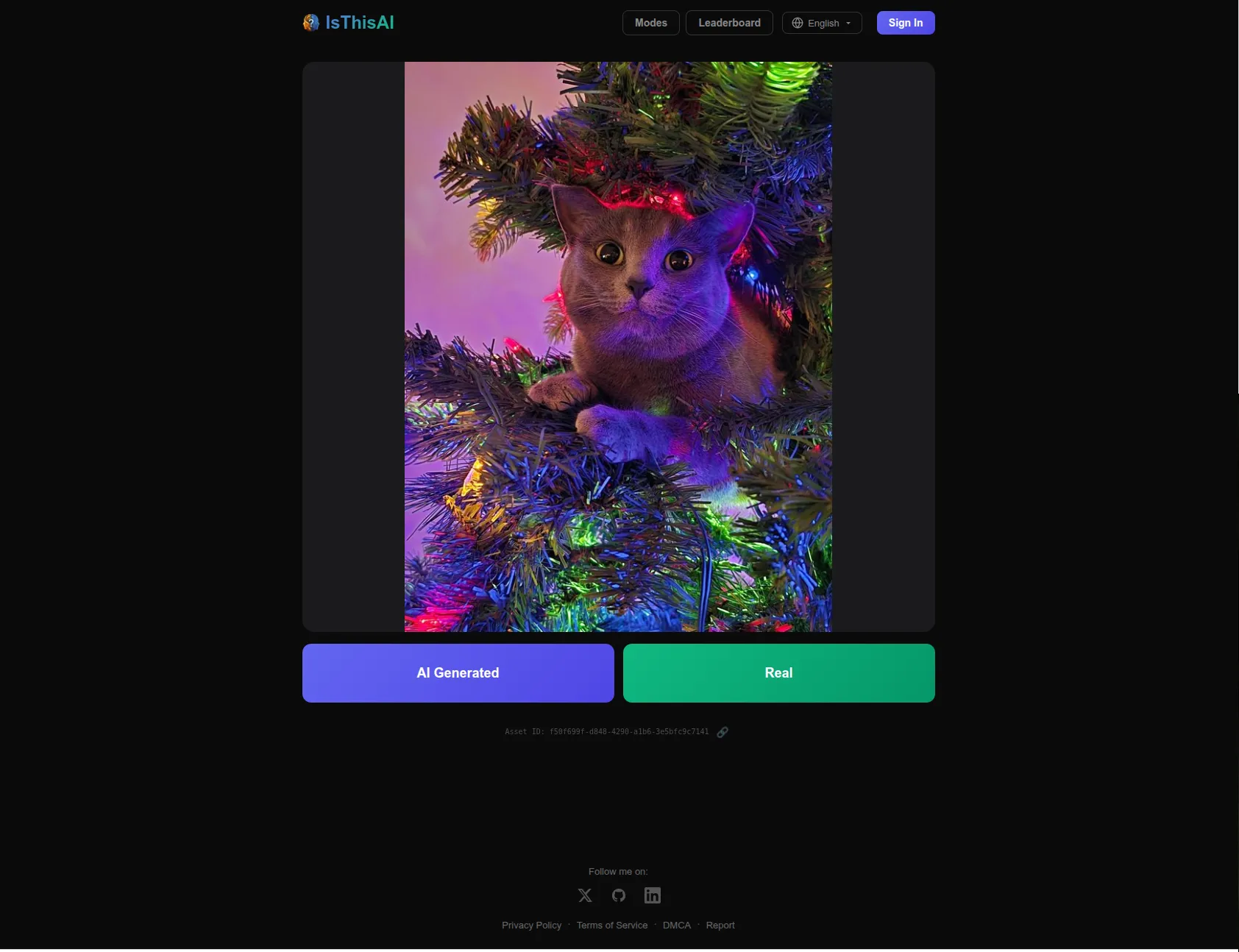
After picking, you see whether you got it right and how the rest of the players voted. The vote distribution turned out to be the most interesting part for a lot of users, especially on the controversial ones.
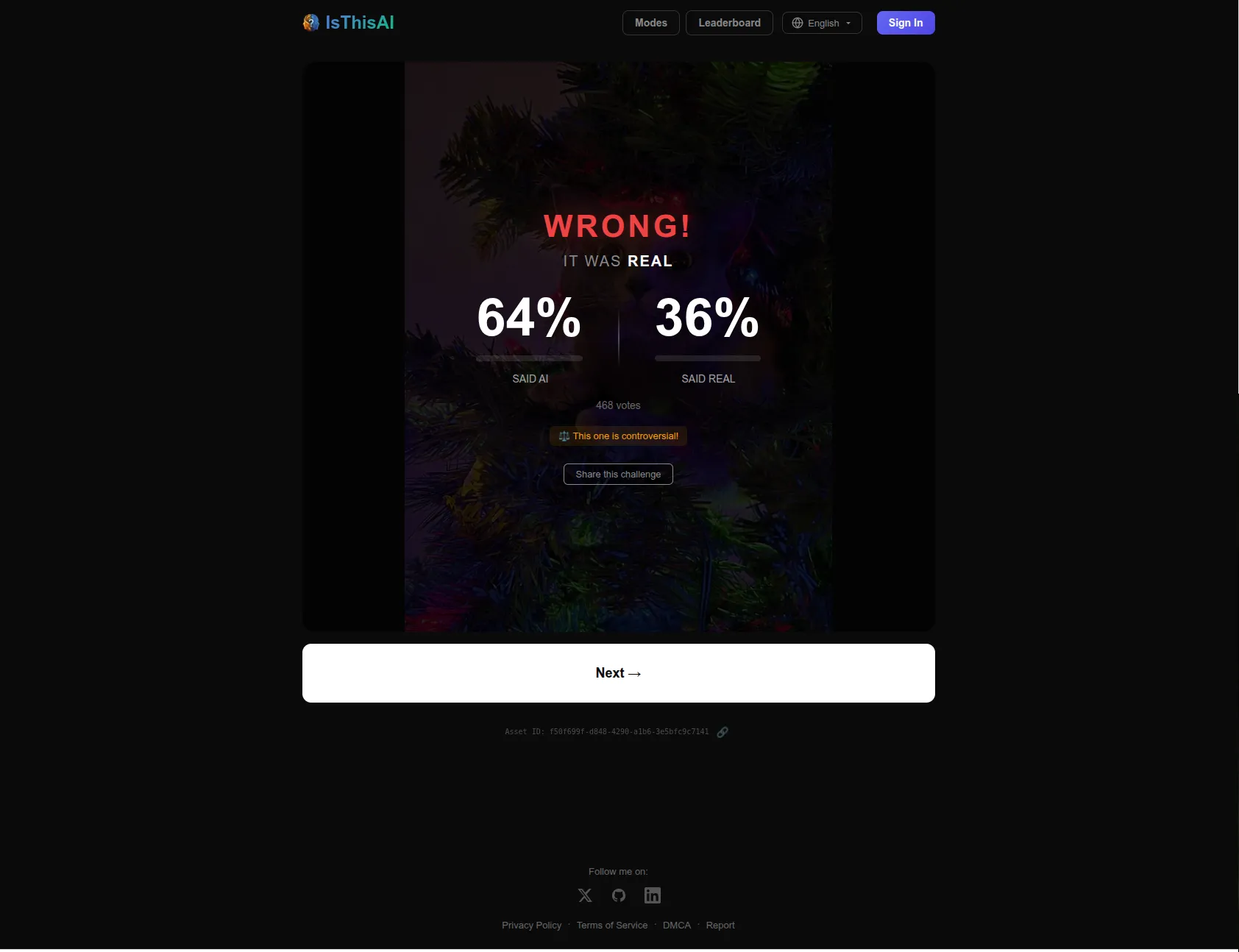
It also worked well on mobile, which is where most of the HN traffic ended up coming from.

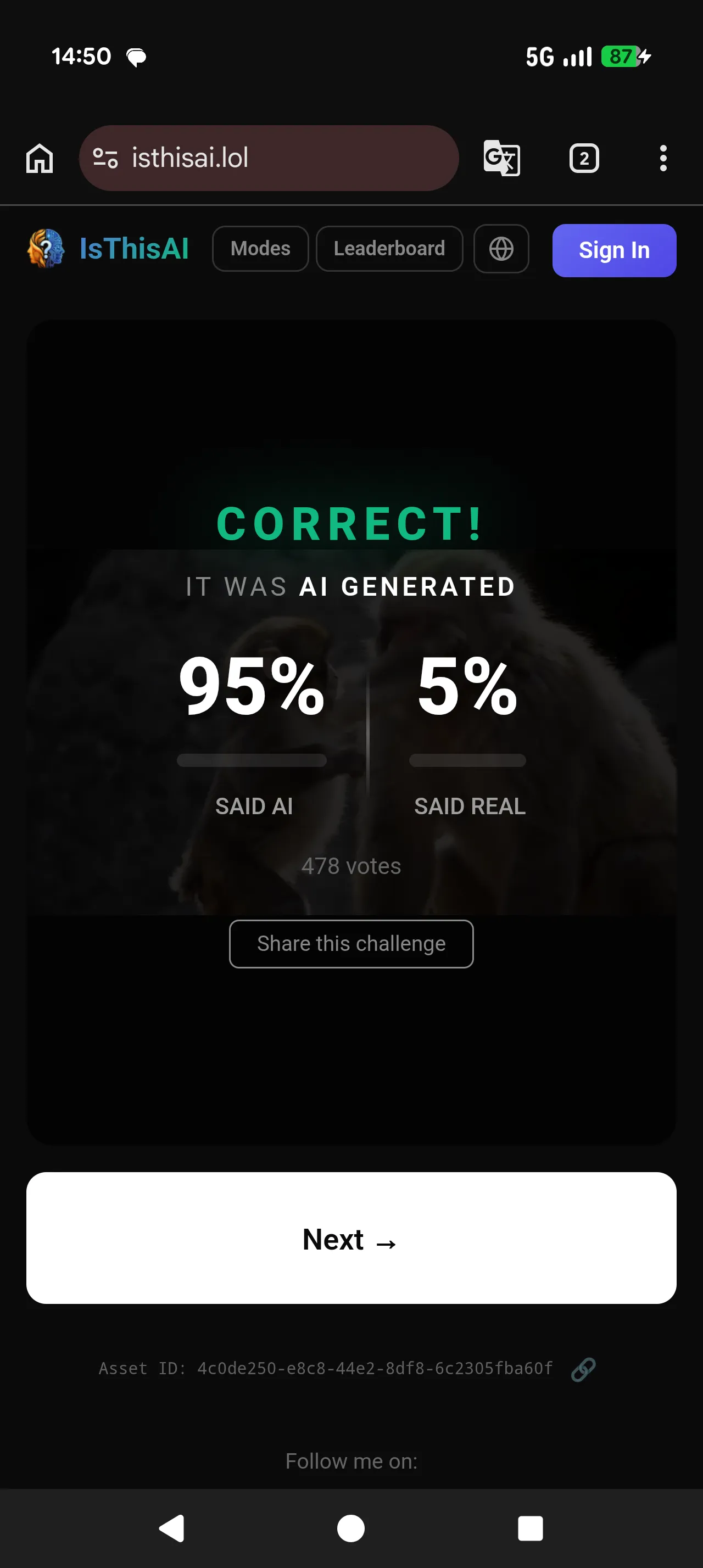
How it went
It got pretty polished and gained a lot of traction after I posted it on Hacker News. The site got over 5k requests in the first few hours, which forced me to bump the gunicorn workers from 2 to 4 mid-thread to clear up a click-handling delay someone reported.
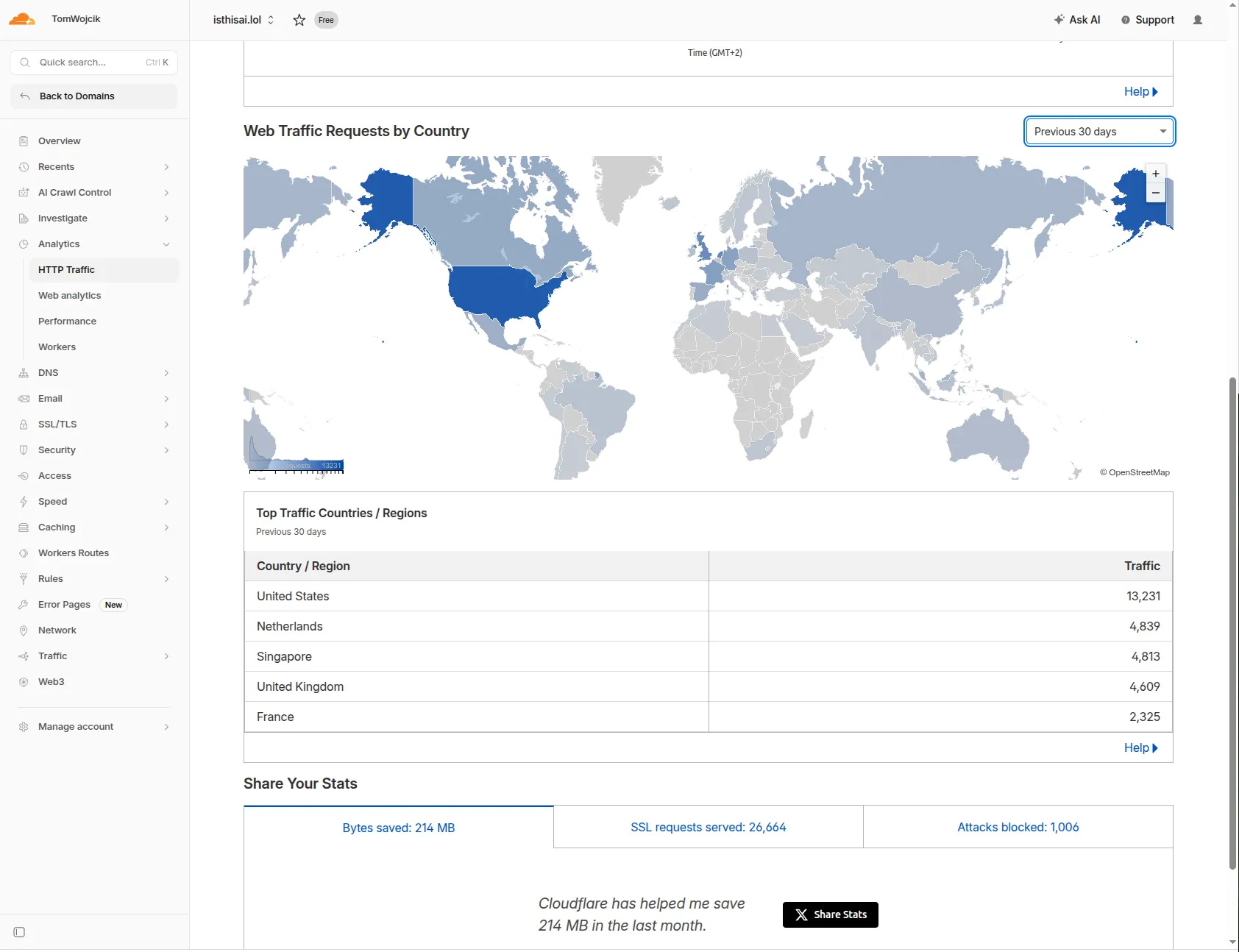
The last (without the ~20k users from HN spike) 30-day Cloudflare view: 4.06k unique visitors, 39k requests, ~1GB served, 214MB cached.
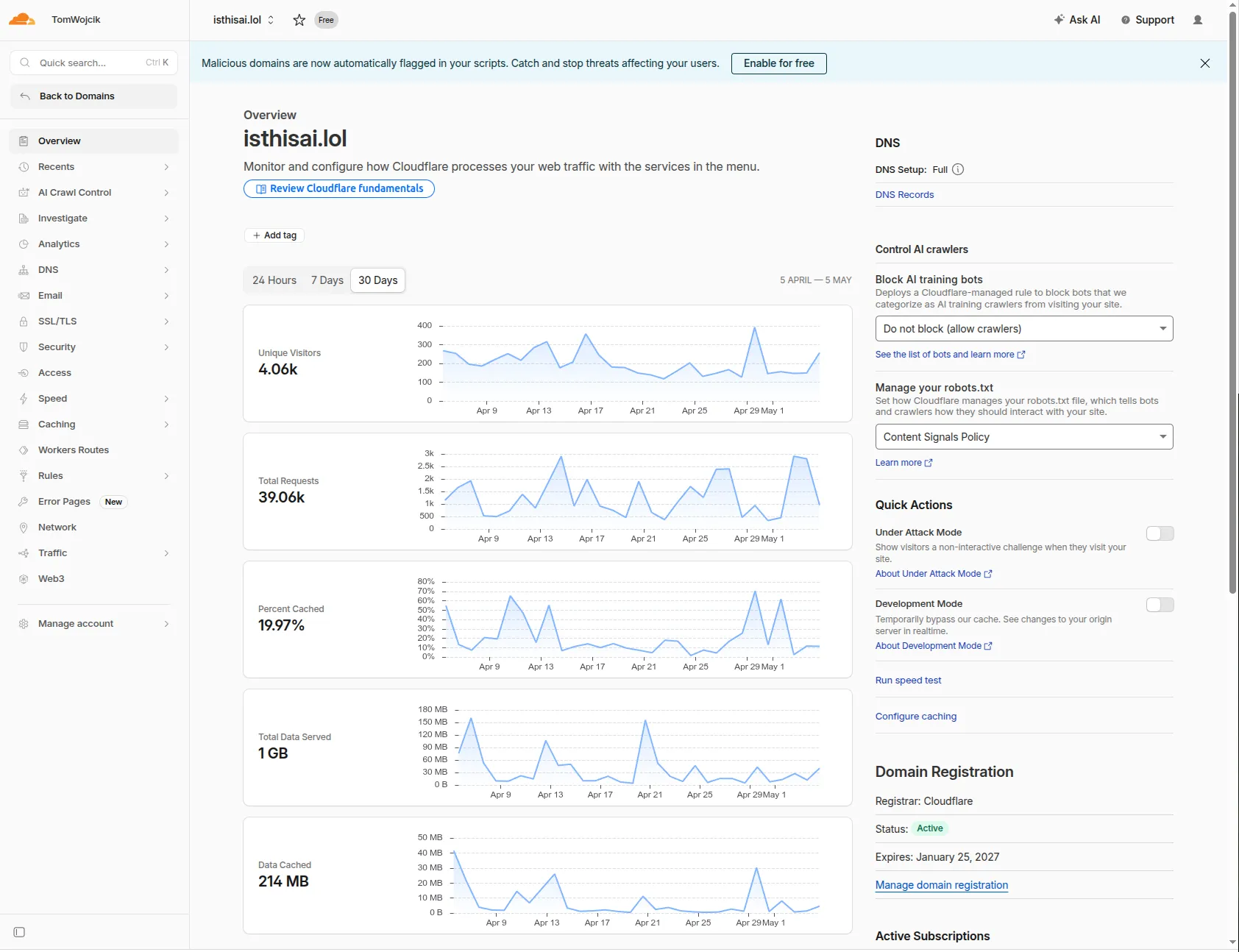
Most of the traffic came from the US, with the UK, Singapore, and France close behind.
Technically the site was snappy. All assets were cached on the Cloudflare edge, so it was running almost for free. Lighthouse scores stayed in the 96+ range across the board.
Feedback from Hacker News
The thread surfaced four clear themes:
It works well as a family game. Multiple commenters said they would use it with parents or relatives. jayteedee joked they would make their parents do 5 rounds before fixing the wifi, then came back later with an update saying the parents actually enjoyed it and were aware of how often they fall for AI videos. edarchis framed it as a way to start a conversation: each person explains their guess, which “shuts the mouth of those who think they know better”.
Provenance is the unsolved problem. Several people asked how the labels are verified. looperhacks asked how I know which videos are AI, surround followed up with “how do you know if it’s real?”, and Melatonic pointed out that “AI generated” vs “real” misses a real category (think Photoshop). My short answer was SynthID, obvious tells, and Reddit threads as proof, but a satisfying answer means curating evidence per asset, which does not scale for a side project.
Can humans even be trained? wastewastewaste said the site is a guesser, not a trainer. tonelord made the line that stuck with me: human brains are already far behind detecting AI generated content as of 2025/26, and we probably will not catch up. ebonnafoux agreed more bluntly, some AI photos genuinely cannot be distinguished from real ones.
Smaller asks. GSSmarin wanted to replay the asset after picking. monkaiju asked what the “this one is controversial” label actually meant (split votes vs unknown ground truth). mosselman asked why the video controls were hidden (to keep it a game, not a frame-by-frame inspection).
What I learned about how people use it
I added leaderboards and a few different game types, but in practice almost everyone stuck to the default “random guess” mode. That changed how I thought about the product. It is not really a game, it is closer to a Tinder for AI detection: tap, decide, swipe, repeat. The loop people actually wanted was the simplest one.
That also meant the asset quality was the whole product. I put a lot of effort into curating the pool, finding examples that were genuinely ambiguous rather than obvious tells, and that turned out to matter much more than any meta-mechanic on top.
Under the hood
A few engineering bits worth pulling out:
- “Controversial” is a number, not a label. Each asset has a quality score from 0 to 100, defined as the maximum deviation from a 50/50 split. Unanimous votes score 100, an even split scores 0, and the latter is what gets the “this one is controversial” tag (which is what
monkaijuwas asking about on HN). A Celery task recomputes it every 10 minutes. - Game IDs are deliberately unguessable. Each game ID is a UUIDv7 XORed with 128 bits of randomness, and game secrets are compared in constant time. Overkill for a guessing game, but it kept anyone from enumerating asset IDs to scrape labels.
- No repeats, without server-side session state. The frontend keeps the last 80 seen assets in localStorage and sends them as an
X-Recent-Assetsrequest header. The backend just excludes them from challenge selection. Cheap, stateless on the server, and good enough because nobody needs cross-device dedup for a game. - Vote counting is intentionally racy. Votes go through Redis with no locks or transactions. There is a real race between
HGETALLandDELETEwhere votes written in between can be lost. I picked performance over consistency on a small VPS, on the grounds that “is this AI” is a popularity poll, not a financial ledger. An honest tradeoff, and one I would make again.
Why it’s winding down
Two problems made it hard to keep going:
- Maintenance would have been huge. Users (rightfully) expected proof and an explanation of what makes a given asset AI generated. That kind of curation per asset does not scale for a side project.
- The premise stopped working. Within a few months we went from “that’s probably an AI” to genuinely not being able to tell. Looking at ChatGPT 5.5, Nano Banana 2, and most importantly Bytedance’s models, the gap basically closed. As of today (May 5, 2026), almost everything looks real.
I do not see a path to monetize it via ads, and I do not want to spend my time collecting realistic looking content just to tell someone “no, this one is real”. It stopped being fun once the answer became “you genuinely cannot tell”.